
Personal Projects
Company rebrand/pivot detector
During my time at Beauhurst, one of my regular tasks was to compare company blurbs, which are short self-descriptions scraped from websites, across different time periods. The goal was to identify cases where a company had rebranded, meaning a significant change in its public image, or pivoted, meaning a change in its products or services. This was previously a time-consuming manual and subjective process, so I took the initiative to automate it by developing a tool called PR Detector. I developed a natural language processing model using NLTK to automatically detect when such changes occurred. The model normalises and embeds the text of each blurb into a semantic space where similarity can be quantified, allowing potential rebrands or pivots to be flagged for review. This saved a substantial amount of analyst time, and the concept was later incorporated into other workflows within the company.
code.

Predicting film viewer ratings
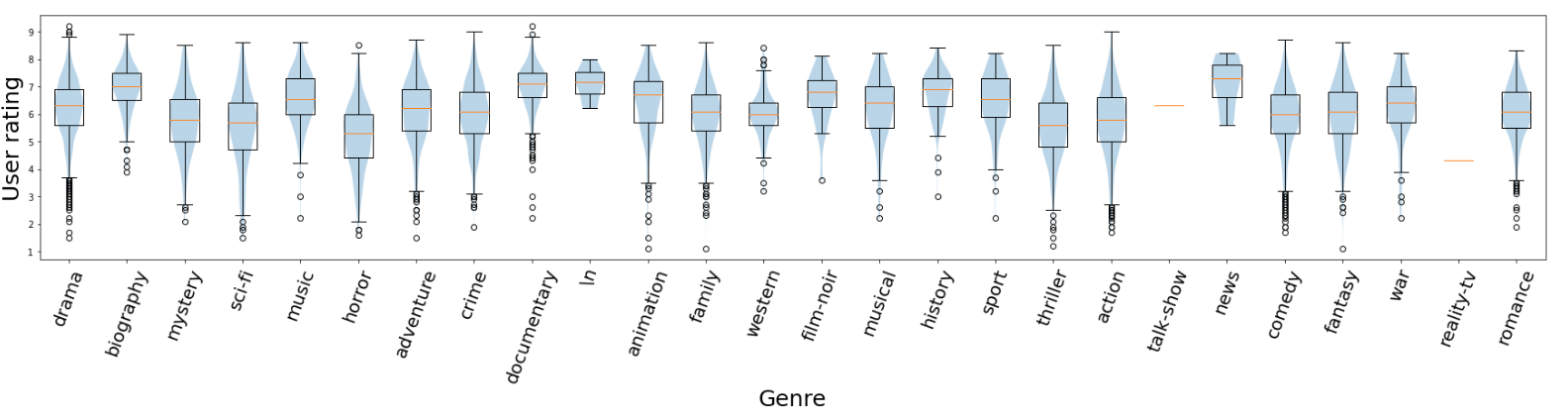
In this project I explored whether it is possible to predict a film’s IMDb viewer rating using only information available prior to wide release, such as the streaming platform, Rotten Tomatoes critic score, genre, and other metadata. I collected and cleaned data from IMDb’s title database, engineered relevant features, and implemented a fully reproducible environment. Exploratory analysis and predictive modelling were performed in Jupyter notebooks with pandas and scikit-learn. The project had two main motivations: first, as a data science exercise to practise feature engineering, model selection, and interpretability, and second, to investigate a personal interest of mine: how early film attributes might forecast audience sentiment. The results showed that while expected factors such as critic ratings and genre were strong predictors, less obvious features like the streaming platform also had a notable effect, with films released on Hulu showing a significant negative correlation with final viewer ratings. Overall, the project demonstrates my ability to design and execute an end-to-end data science workflow, from data acquisition to analysis and interpretation.
code.
Implementing machine learning algorithms
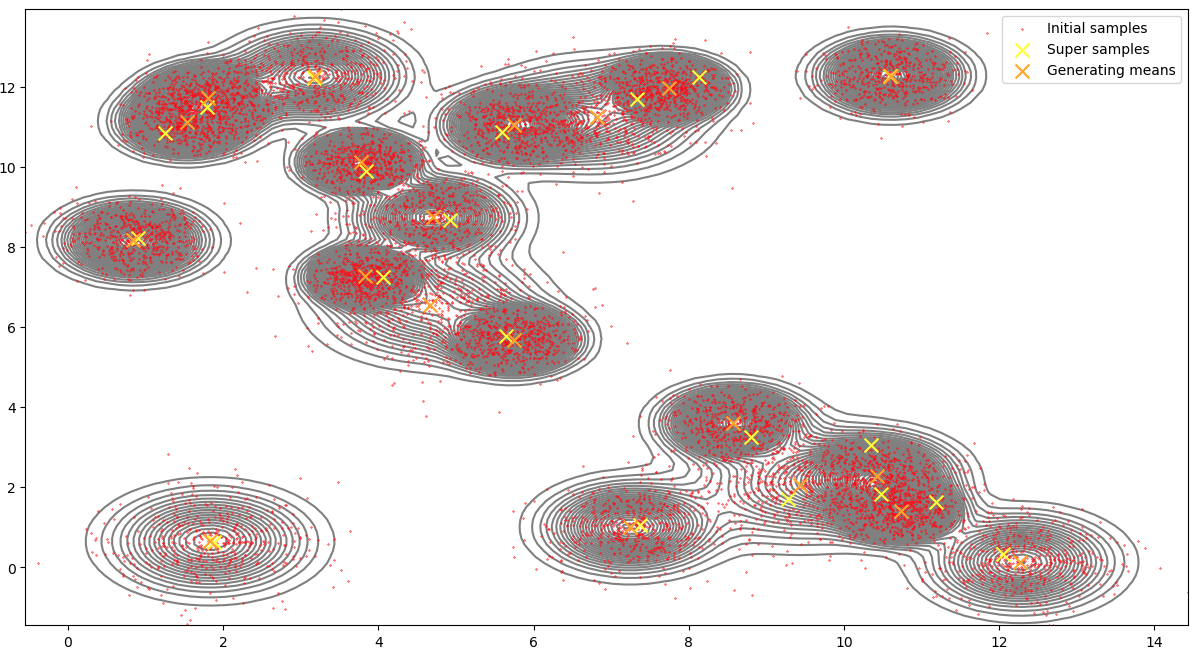
During my PhD in computational statistics and data science, I often reimplemented algorithms from research papers in order to further my understanding. I have collected several of my favourite approaches in public repositories. For example, I wrote my own implementation of Kernel Herding, one of the earliest and most intuitive methods for distribution compression. The algorithm iteratively optimises representative samples targeting a dataset, revealing which regions of the data space are most influential in capturing the overall distribution.
Additional projects include a conditional density estimator, a kernel density estimator for univariate data, a local regression model and a Gaussian Process classifier.